Transformers
title: Transformers date: 2024-01-02 12:00:00 categories:[AI, Text Processing] tags: [ML, AI, GenAI] author: “Dev” —
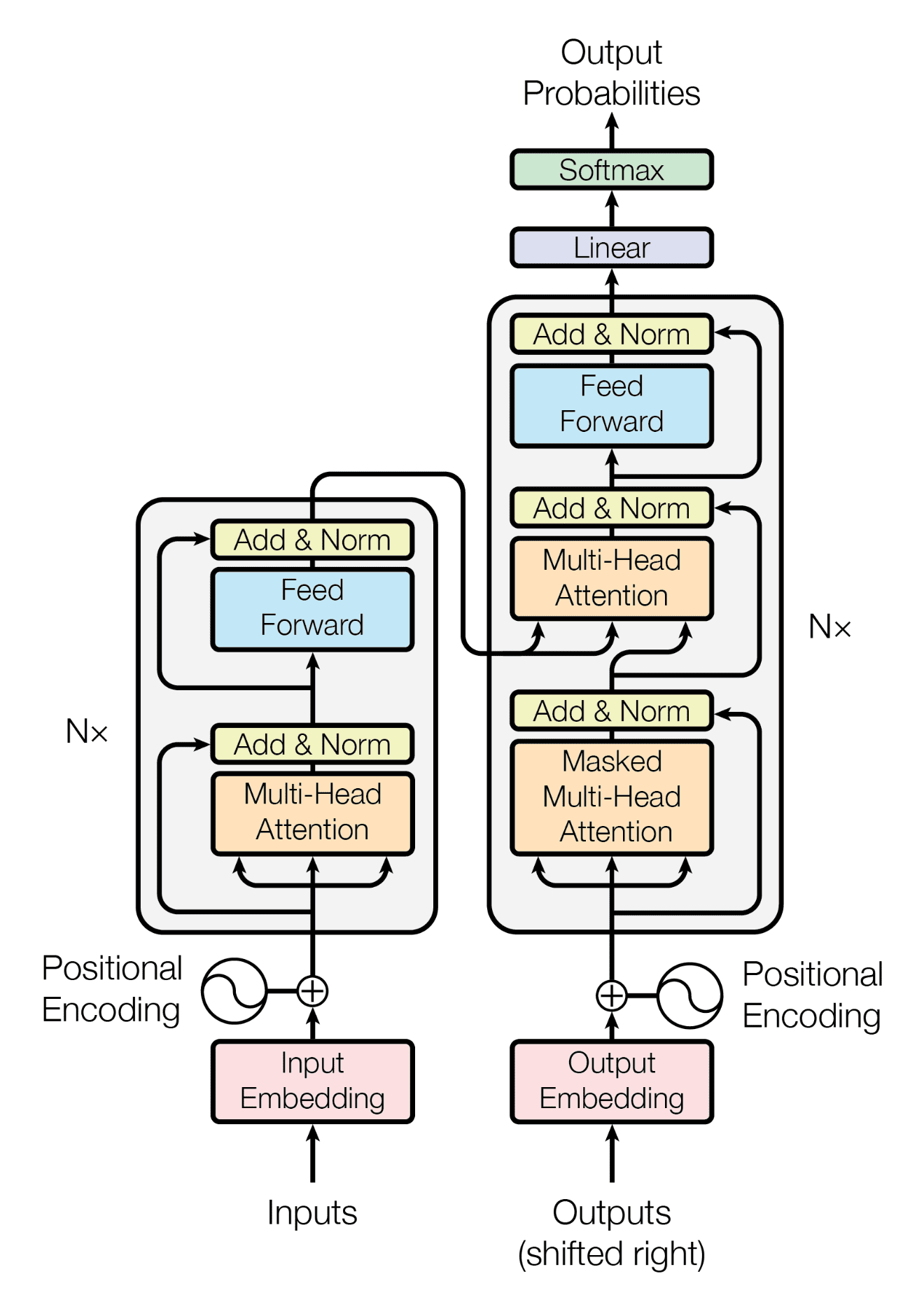
Text Generation with Transformers: Fine-Tuning for Specific Tasks
Transformers have revolutionized Natural Language Processing (NLP), achieving state-of-the-art results in various tasks, including text generation. Unlike recurrent neural networks (RNNs), transformers process entire sequences in parallel, enabling them to capture long-range dependencies more effectively. This blog post dives into fine-tuning a pre-trained transformer model for a specific text generation task.
What are Transformers?
At their core, transformers rely on the mechanism of self-attention. Self-attention allows the model to weigh the importance of different words in a sentence when processing 1 a particular word. This helps the model understand the context and relationships between words.
1. hackernews-kappa.vercel.app
DeepSeek’s transformer architecture introduced several key innovations that differentiate it from standard transformer models like those used in GPT series. Here are the main architectural differences:
Multi-Query Attention (MQA): Instead of using multiple sets of key and value projections per attention head (as in multi-head attention), DeepSeek uses a shared key and value projection across all heads while maintaining separate query projections. This significantly reduces computational requirements and memory usage while maintaining performance.
RoPE (Rotary Positional Embedding): DeepSeek employs rotary positional embeddings instead of absolute or learned positional embeddings. RoPE encodes position information directly into the attention computation through a rotation matrix, which helps the model better understand relative positions and extends more effectively to sequences longer than those seen during training.
Grouped-Query Attention (GQA): An intermediate approach between multi-head and multi-query attention where key and value projections are shared among groups of attention heads rather than completely shared or completely separate. This offers a balance between computational efficiency and representational power.
SwiGLU Activation: DeepSeek uses SwiGLU activation functions in the feed-forward networks instead of traditional ReLU or GELU activations. SwiGLU combines gating mechanisms with swish activations to improve gradient flow and model capacity.
Normalization Placement: DeepSeek implements “pre-normalization” where layer normalization is applied before the self-attention and feed-forward blocks rather than after them. This pre-norm design helps stabilize training for very deep models.
Parallel Structure: The model uses a parallel structure where the residual connections bypass both the attention and feed-forward blocks in parallel rather than in series, which can improve gradient flow during training.
Larger Context Windows: DeepSeek models were trained with significantly larger context windows than earlier models, enabling them to process and reason over much longer sequences of text.
These architectural choices collectively allow DeepSeek models to achieve high performance while maintaining computational efficiency, especially for long-context reasoning tasks.
Why Fine-Tuning?
Pre-trained transformer models, like BERT, GPT, and RoBERTa, have learned rich language representations from massive datasets. Fine-tuning these models on a smaller, task-specific dataset allows us to adapt their knowledge to our specific needs without training from scratch, which is computationally expensive and requires vast amounts of data.
Fine-Tuning for Text Generation: A Practical Example
Let’s consider the task of generating creative text, specifically short poems. We will use the transformers library from Hugging Face, which provides easy access to pre-trained models and fine-tuning tools.
1. Installation:
First, install the necessary libraries:
Bash
1
pip install transformers datasets accelerate
2. Loading a Pre-trained Model and Tokenizer:
We’ll use GPT-2 as our base model:
Python
1
from transformers import GPT2LMHeadModel, GPT2Tokenizer
3. Preparing the Dataset:
For this example, let’s assume you have a text file (poems.txt) where each line is a short poem. You’ll need to tokenize the text:
Python
1
from datasets import load_dataset
4. Fine-Tuning the Model:
Now comes the core part: fine-tuning. We’ll use the Trainer class from the transformers library:
Python
1
from transformers import TrainingArguments, Trainer
5. Generating Text:
After fine-tuning, you can generate new poems:
Python
1
prompt = "The moon shines bright,"
Key Parameters for Generation:
max_length: The maximum length of the generated text.num_return_sequences: The number of different sequences to generate.temperature: Controls the randomness of the generation. Lower values (e.g., 0.2) make the output more deterministic, while higher values (e.g., 1.0) make it more creative.
Conclusion:
Fine-tuning transformers is a powerful technique for adapting pre-trained models to specific text generation tasks. By using the transformers library, you can easily experiment with different models and datasets to achieve impressive results. Remember to adjust the hyperparameters and training arguments to optimize for your specific use case. This blog post provides a basic introduction; further exploration of advanced techniques like beam search and different decoding strategies can further enhance your text generation capabilities.